Using SQL to Investigate Data Accuracy in Improve Detroit Reports
NOTE: This analysis was done prior to the deprecation of the Improve Detroit dataset which now can be found here. Analysis findings may no longer align. Sharing just for my own interest to document the project work.
While exploring the Looker Studio Dashboard for the City’s 311/Improve Detroit reports, it became clear that the dataset needed a closer look. Two key issues jumped out: many reports were missing address details, and others didn’t line up correctly with the city council districts they were supposed to be in.
After having previously developed a BigQuery database to store this dataset, I determined that it was a good opportunity to analyze the data with SQL and identify some answers to my interest.
Digging into the reports with missing addresses, they generally fell into three categories:
- Reports with redacted addresses.
- Reports where the address simply began with “Detroit” but didn’t include a street name or number.
- Reports labeled “None Detroit,” offering no location context at all.
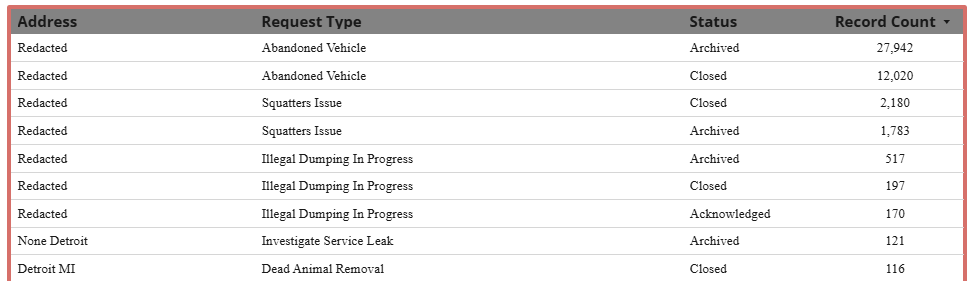 The first, reports where the address was redacted, didn’t have location data associated with the reports. 44,858 reports in total [~7.3% of all reports]. All of which fell into three report type categories:
The first, reports where the address was redacted, didn’t have location data associated with the reports. 44,858 reports in total [~7.3% of all reports]. All of which fell into three report type categories:
| Request Type | Report Count |
|---|---|
| Abandoned Vehicle | 39,966 |
| Squatters Issue | 3,983 |
| Illegal Dumping In Progress | 909 |
SELECT Request_Type_Title,COUNT(*)
FROM `improve-detroit-data.improve_detroit_reports.improve_reports`
WHERE Address = 'Redacted'
GROUP BY Request_Type_Title
ORDER BY COUNT(*) DESC
The second, reports that had addresses that started with “Detroit”, were a mix of locations that started with “Detroit”, like “Detroit Riverwalk”, and combinations of city name, state, zip code but without an actual address. 520 reports in total, all with location data.
The third, reports marked “None Detroit”, 121 of them in all, were for “Investigate Service Leak” and had location data associated with them.
SELECT Request_Type_Title,COUNT(*)
FROM `improve-detroit-data.improve_detroit_reports.improve_reports`
WHERE STARTS_WITH(Address, "None")
GROUP BY Request_Type_Title
ORDER BY COUNT(*) DESC
After reviewing the address issues, attention turned to another concern: reports assigned to the wrong city council district.
A total of 16,053 reports—approximately 2.6% of all submissions—were found to be misaligned, meaning the district listed in the report did not match the district where the incident actually occurred. The discrepancy rates varied widely by district:
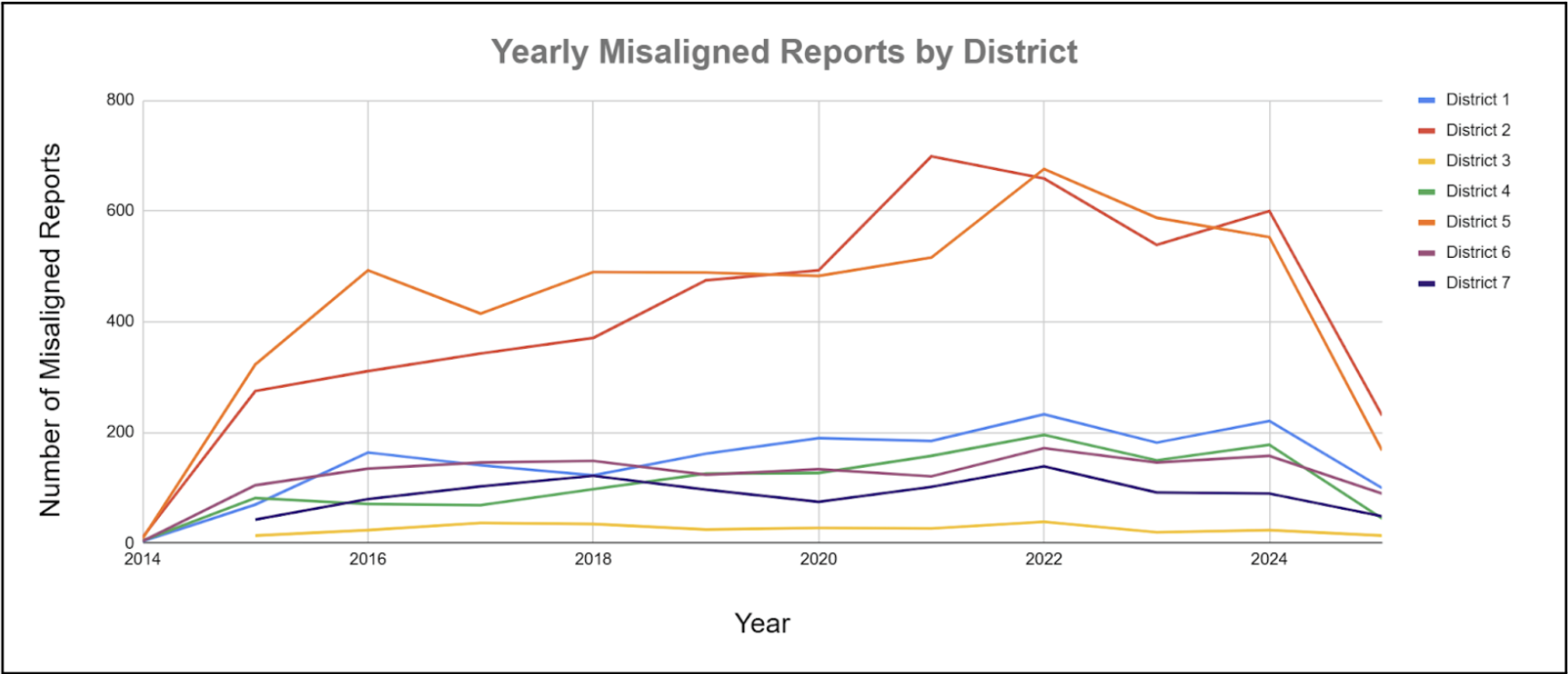
| Council District | Percentage of Total Misaligned Reports |
|---|---|
| District 1 | 11.06% |
| District 2 | 31.19% |
| District 3 | 1.79% |
| District 4 | 8.13% |
| District 5 | 32.41% |
| District 6 | 9.24% |
| District 7 | 6.18% |
SELECT
r.Council_District,
COUNT(*) AS num_misaligned_reports
FROM
`improve-detroit-data.improve_detroit_reports.improve_reports` r
JOIN
`improve-detroit-data.improve_detroit_reports.city_districts` d
ON
SAFE_CAST(r.Council_District AS STRING) = SAFE_CAST(d.DistrictNu AS STRING)
WHERE
r.Location IS NOT NULL
AND NOT ST_WITHIN(r.Location, d.District_Geography)
GROUP BY
r.Council_District
ORDER BY
num_misaligned_reports DESC;
To identify these inconsistencies, I did a spatial analysis to compare the geographic coordinates of each report with official council district boundary shapefiles that I was able to get uploaded into BigQuery. This allowed me to flag reports where the listed district did not match the actual geographic location. The resulting map highlights these discrepancies, especially in Districts 2 and 5, which had the highest number of misclassified reports.
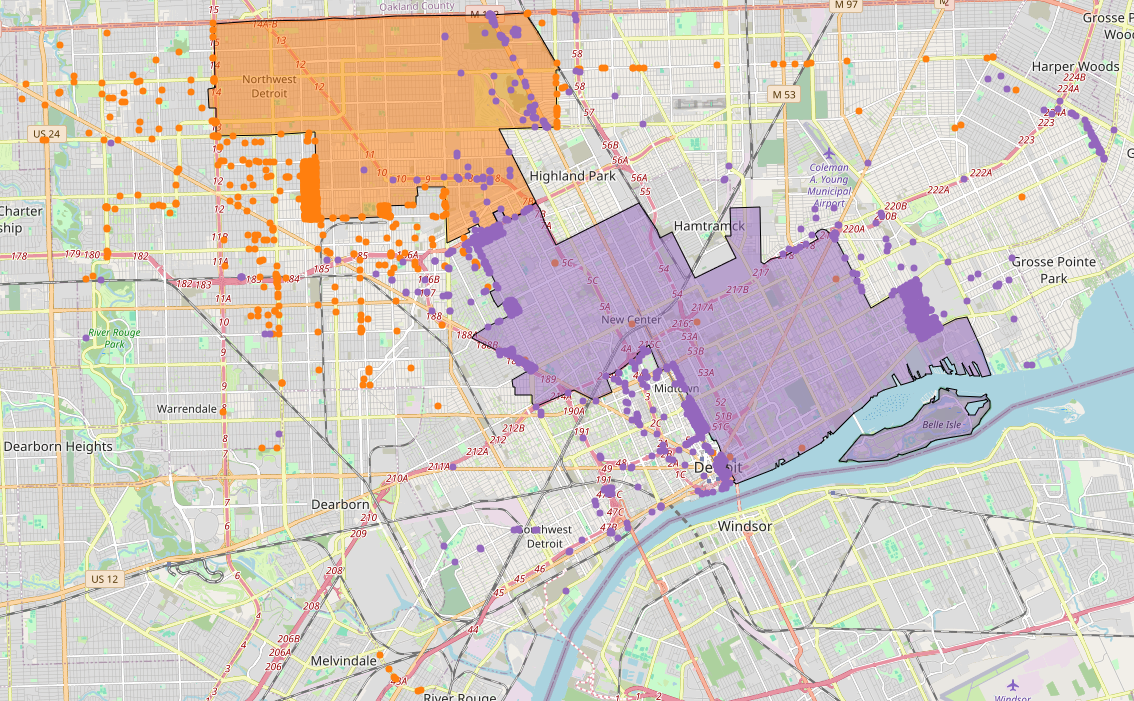
This analysis reveals a possible reliability issue in the public-facing dataset when analyzed at the district level. As Detroit prepares for an upcoming shift in council district boundaries, this presents a timely opportunity to improve the accuracy and consistency for all the existing and coming reports.
NOTE: The dataset did, in fact, get updated so this could have been corrected at the time of posting.